
O Diário Eletrônico Oficial do Município de São Caetano do Sul publicou em 17 de março de 2020 uma lista de Autos de Infração de Trânsito e as respectivas Notificações das Autuações de Trânsito expedidas no período de 01/03/2020 a 15/03/2020. A lista se inicia na página 4 e se estende até a página 38.
O formato do arquivo é PDF, contendo 2 colunas.
Como fazer para se obter esta lista em formato adequado para estudo? Copiar e colar cada bloco e inserir em uma planilha é uma solução. Entretanto, caso se queira refazer este mesmo trabalho com outro período, o trabalho manual se mantém.
Considerando que há interesse em automatizar esta garimpagem de dados, foi criado um programa em Python, que busca dentro do arquivo PDF cada página e, em cada uma delas, localiza o início e fim da tabela.
Par isso, foi utilizada uma biblioteca PyPDF2, essencial para o trabalho. É ela que permite a leitura e tratamento de cada página do arquivo PDF.
O arquivo PDF foi baixado localmente para uso. A partir daí, foi montado o programa (veja mais abaixo o código comentado). Ao executar, o conteúdo extraído fica em uma variável do Spyder (IDE de trabalho com Python). Aí é só copiar e colar em uma planilha para avaliação.
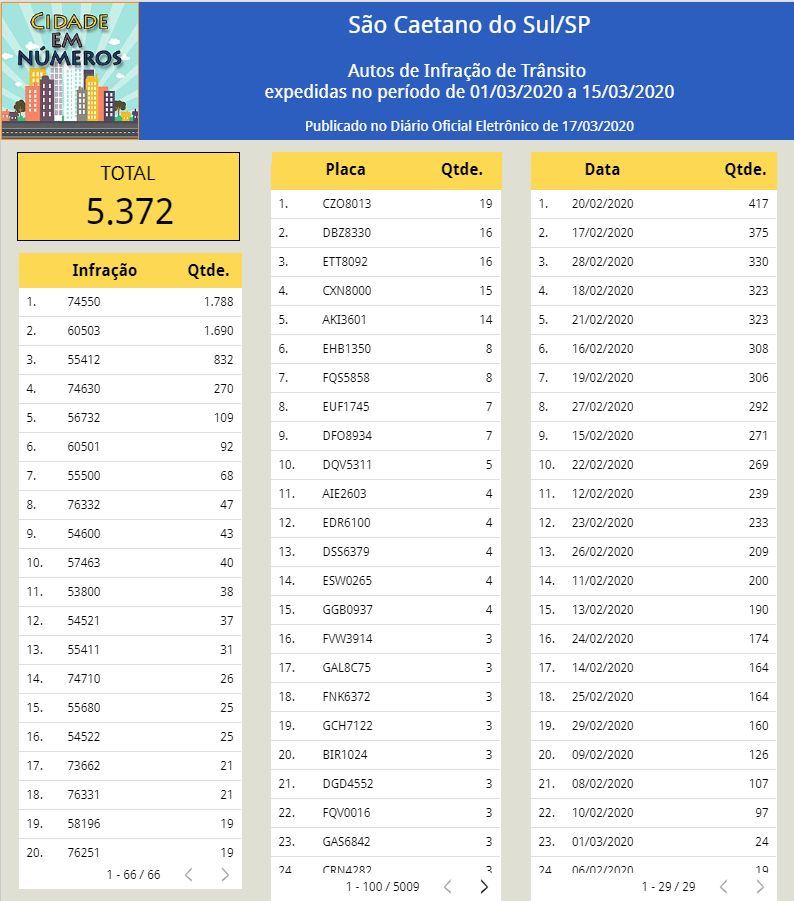
Uma vez que a tabela esteja preparada, é preciso apresentar as informações em visual adequado. Aí entrou em cena o Data Studio da Google. A planilha foi convertida em formato CSV e carregada na nuvem. Usando o Data Studio, foram criados os blocos de apresentação dos detalhes consolidados das informações coletadas. O resultado final pode ser visto nesta imagem, que foi publicada no site Cidade em Números.
CÓDIGO EM PYTHON COMENTADO
#importando o módulo
import PyPDF2
#criando um objeto PDF
pdfFileObj = open("Diario Oficial Eletronico 17032020.pdf", "rb")
#criando um objeto leitor
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
#pegar da página 4 até a 38 (onde tem as multas)
todoTexto = ""
for x in range(3, 39):
print("*********************************Página {}".format(x))
pageObj = pdfReader.getPage(x)
todoTexto = todoTexto + pageObj.extractText()
#só para preservar o conteúdo completo da tabela, como segurança
todoTextoReserva = todoTexto
#localiza o texto que se encontra antes da tabela
textoPesquisa = "Prazo Defesa"
inicioDestaTabela = todoTexto.find(textoPesquisa) + len(textoPesquisa)
#retira o texto do início até o início da primeira tabela
todoTexto = todoTexto[inicioDestaTabela:]
while True:
#localiza a linha em branco no final da tabela
textoPesquisa = " \n"
fimDaTabelaOpcao1 = todoTexto.find(textoPesquisa, inicioDestaTabela)
textoPesquisa = "Auto Infração"
fimDaTabelaOpcao2 = todoTexto.find(textoPesquisa, inicioDestaTabela)
#escolhe o menor índice para delimitar o início da próxima tabela
if fimDaTabelaOpcao1 >= 0 and fimDaTabelaOpcao2 >= 0:
fimDaTabela = min(fimDaTabelaOpcao1, fimDaTabelaOpcao2)
else:
#se um deles for -1, pega o outro
fimDaTabela = max(fimDaTabelaOpcao1, fimDaTabelaOpcao2)
#mostra o pedaço onde localizou
print("Fim: {}".format(todoTexto[fimDaTabela-10:fimDaTabela+10]))
#se não tem mais informação, interrompe
if fimDaTabela < 0:
#pega o último bloco antes de interromper
textoSeparado = textoSeparado + todoTexto[inicioDestaTabela:fimDaTabela]
print("***Pegou o último bloco e encerrou***")
break
#prepara o conteúdo para juntar com os anteriores
blocoTexto = todoTexto[inicioDestaTabela:fimDaTabela]
#remove espaços antes do final da linha
blocoTexto = blocoTexto.replace(" \n", "\n")
#remove espaços no início da linha
blocoTexto = blocoTexto.replace("\n ", "\n")
#remove 2 trocas de linha
blocoTexto = blocoTexto.replace("\n\n", "\n")
#separa o texto útil (corresponde à tabela
textoSeparado = textoSeparado + blocoTexto
#remove todo o bloco do texto base
todoTexto = todoTexto[fimDaTabela:]
#verifica se bloco ficou sem informação
if len(todoTexto) < 10:
break
#localiza o texto que inicia nova da tabela
textoPesquisa = "Prazo Recurso"
inicioDestaTabelaOpcao1 = todoTexto.find(textoPesquisa)
textoPesquisa = "Prazo Defesa"
inicioDestaTabelaOpcao2 = todoTexto.find(textoPesquisa)
#escolhe o menor índice para delimitar o início da próxima tabela
if inicioDestaTabelaOpcao1 >= 0 and inicioDestaTabelaOpcao2 >= 0:
inicioDestaTabela = min(inicioDestaTabelaOpcao1, inicioDestaTabelaOpcao2)
else:
#se um deles for -1, pega o outro
inicioDestaTabela = max(inicioDestaTabelaOpcao1, inicioDestaTabelaOpcao2)
#se não tem mais informação, interrompe
print("Início {}: {}".format(inicioDestaTabela, todoTexto[inicioDestaTabela-10:inicioDestaTabela+10]))
if inicioDestaTabela < 0:
print("********* Não achou mais tabela *********")
break
#se não terminou, acrescenta o tamanho da string pesquisada
inicioDestaTabela = inicioDestaTabela + len(textoPesquisa)
#fechando o objeto PDF
pdfFileObj.close()